301 Redirects and Reversing a 301 Redirect
On large sites there’s often a need to redirect pages that move, have rebranded content, or become deprecated over time. Along with maintaining the “search equity” of a page, it’s also important to keep the site usable and coherent for users. This can be challenging to configure and maintain, and even more challenging if a 301 redirect needs to be reversed.
Redirect setup
- Search equity: the “link juice” or how much SEO weight a specific page carries.
- 301 redirect: a “permanent” redirect that will also transfer search equity.
- 302 redirect: a “temporary” redirect that will not transfer search equity.
When a page, or URL, is no longer needed on a site there are a few paths to take. The ideal scenario would be to add a 301 redirect from the deleted page to a new page that is a content-equivalent of the removed page. For example, if the content on page /foo/ is being moved to /bar/, a 301 redirect would be appropriate.
If a page is truly removed, without a replacement, let it 404. Letting search engines and users know that a page no longer exists can be beneficial. Search equity will be forfeited, so investigate if a replacement exists first, but do not redirect to an unrelated page as search engines will penalize ranking if this practice is detected.
Redirect tldr;
- When a page moves, add a 301 redirect to maintain the search equity.
- Do not add 301 redirects for unrelated content pages, search engines will penalize for this behavior.
- A 302 redirect does not maintain search equity.
- A 404 is not a bad thing, especially if there is no content-equivalent to redirect to.
Browser caching of 301 redirects
Browsers cache assets ranging from CSS to images to redirects, all in the interest of loading sites faster for users. If a browser encounters a 301 redirect it will cache the server response so that, if requested again, the browser can serve up the destination straightaway rather than reaching out to the server for the redirect. This standard behavior is demonstrated with Firefox:

Subsequent loads of the same URL will load the 301 redirect from cache, rather than contacting the server, as demonstrated by Microsoft Edge:
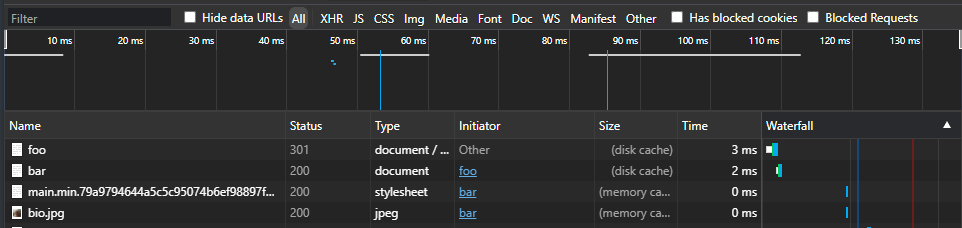
Great! The internet is fast and browsers are being smart by not doing repetitive tasks. However, let’s say the 301 we established was incorrect, and so incorrect it needed to be reversed (/foo/ --> /bar/ to /bar/ --> /foo/).
301 Redirect Reversal
In general, it seems to be the case that when a browser loads it’s cached 301 redirect only to find it’s actually a 301 back to the source, it breaks the infinite loop and goes back to the server to revalidate the requests.
| Browser | Status |
|---|---|
Firefox (v88.0) | ❌ |
Google Chrome (v90.0.4430.72) | ✅ |
Microsoft Edge (v91.0.852.0) | ✅ |
Opera (v75.0.3969.171) | ✅ |
Safari | ❔ |
For Edge, Chrome, and Opera the 301 redirect reversal takes effect immediately and the browsers’ local cache was reset.
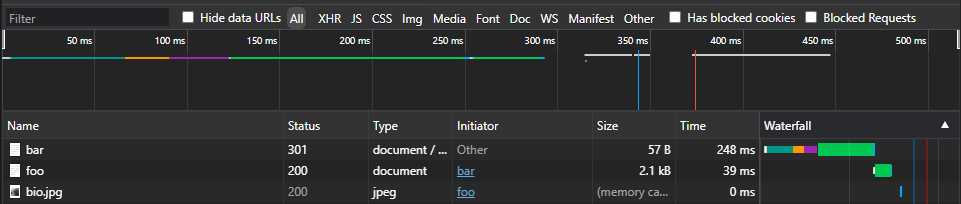
In Firefox, however, the 301 redirect and destination HTML were cached.

When it came time to reverse the 301 redirect, Firefox continued to load the 301 redirect and the destination HTML from cache, rather than reaching out to the server. Opening a new tab and restarting the browser were not enough to invalidate the cache, only explicitly clearing the cache was enough to force the 301 redirect reversal.

There’s still hope! With modified cache-control headers, it’s possible to tell Firefox to reevaluate the cache. One such option is cache-control: no-cache which tells the browser the asset can be cached, but the server “must revalidate each time before using it.” This behavior is exactly what’s needed to force Firefox to reevaluate the cache and allows a 301 redirect reversal to work.